
タイトル長すぎる。
しかもワンライナーdeめちゃくちゃ汚い。
でもこれのお陰でLivedoorブログ(元サイト)→WordPressサイトへの移行が捗った、という自分メモ。
grep 404 /var/log/httpd/access_log | grep archives | grep $(date +%d"/"%b"/"%Y --date "1 day ago") | awk '{print $7}' | sort -n | uniq | sed -e 's#\/archives\/##g' | grep -v cat_ | awk '{ sub(".html.*", ""); print $0;}'| uniq | grep -v -E 'archives|favicon' | sed 's#\*\*\*##g' > hoge.txt ; for i in `grep -v "-" hoge.txt` ; do grep -B1 ${i} ./backupdata.txt | sed -e 's#archives\/##g'; done > ./logs/404chk_`date +%Y%m%d%H%M`.log- 神ワンライナー(汚ワンライナー)作成の経緯
- 対応後
- 神(汚)ワンライナー登場
- 設計思想
- スクリプトの解説
- 1.アクセスログから404だったものを抽出。
- 2.1で抽出したログの中から、前日のものだけを抽出。
- 3.2で抽出したログの中から、https://tech-memo.net/以降の文字列だけを抽出。
- 4.3で抽出した文字列に対し、重複しているものを1つに抽出。
- 5.4で抽出した文字列に対し、</archives/>という文字列だけを削除。(.htaccessに記述しやすくするため)
- 6.5で抽出した文字列に対し、<cat_>という文字列を含む結果行を削除。
- 7.6で抽出した文字列に対し特定のファイルへのアクセス先の行は削除し、再度重複を削除
- 8.7で抽出した文字列で不要な文字列を削除しhoge.txtというファイルに出力
- 9.backupdata.txtというエクスポートファイルを整形したテキストに対して、出力したhoge.txtの中の文字列を1行づつgrepで検索し、最終的な結果をログに出力。
- backupdata.txtの中身
- 5月23日に実行したスクリプトの結果
- この汚ワンライナーの問題点
- 結論
神ワンライナー(汚ワンライナー)作成の経緯
先日サイトの引っ越しをした。その際に元サーバーで以下の設定を実施した。
その時に元サイトの管理画面で元サイト→新サイトへリダイレクトの処理を設定した。
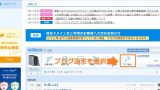
移動元サイト(Livedoorブログ)側のリダイレクト設定
移動元の全てのサイトから移動先サイトへの転送設定。
- 移動元:http://tech-memo.blog.jp→移行先:https://tech-memo.netへのトップページのFQDNの転送設定
- 移動元:http://tech-memo.blog.jp→移行先:https://tech-memo.netへのサイト全体の転送設定
上記を実施することで以下に対して301リダイレクトでの転送が可能にした。
http://tech-memo.blog.jp/archives/***.html → https://tech-memo.net/archives/***.html
これだけでは足りない
移動元サイトは、http://tech-memo.blog.jp/archive/***.htmlというページで記事が公開されるように設定していた。
しかし移動先サイトでは、https://tech-memo.net/archives/***.htmlというページは存在せず。
記事が公開されるページはhttps://tech-memo.net/?p=NNNNに変更。
上記の理由で、https://tech-memo.net/archives/***.htmlにアクセスしてきたサイトをhttps://tech-memo.net/?p=NNNNに転送する必要があった。
厳密には必要ないけど、何となくやりたくなったのでリダイレクトする設定やってみた。
問題点
恐ろしいことに、元サイトのhttps://tech-memo.net/archives/***.htmlと、新サイトのhttps://tech-memo.net/?p=NNNNには、何の法則性もなかった。
特に元サイトの***.htmlの****はブログ運営会社の都合で生成されているので新サイトの?p=NNNNのNNNに紐づけようとすると手作業で紐づけるしかなかった。
暫定対応
嫌々手作業で対応。。。
1.とりあえずアクセス数の多いページ(約50件)を抽出し、移行時に生成した元サイトのエクスポートデータ(テキスト)に対して、件名と移動元のURLを元に、手動で移動先のURLを掘り起こし、タイトルとURLの紐づけ調査を手動で捏ね上げる。
2.1で取得したタイトルを、新サイトの検索欄にペースト&検索ボタン押下し新サイトのURLを手作業で取得。
3.移動元、移動先のURLを取得できたので後は機械的に(手動で).htaccessに記述。
4.2、3の手順を約50件分繰り返す。
辛抱たまらんかった。
対応後
その後も、時折未設定のhttps://tech-memo.net/archives/***.htmlに対してアクセスが行われ、404エラーが出力され続ける。
これらに関してはスルーしてもよいのだけれど、何となく気になっていたので見つけたら手作業で直していた。
しかし、面倒くさい。
この面倒くささは、何とかならんのか。ならんのか。ならんのか。
神(汚)ワンライナー登場
満を持してワンライナー登場。
設計思想
1.1日1回0時以降に実行。
2.手作業を少しでも減らす。
スクリプトの解説
見づらくなるので、パイプは割愛。
1.アクセスログから404だったものを抽出。
タイトルの通り。https://tech-memo.net/archives配下に対してアクセスし404の文字列を抽出。
grepのAND検索は1回で完了できるようになりませんかね。
grep 404 /var/log/httpd/access_log | grep archives 2.1で抽出したログの中から、前日のものだけを抽出。
タイトルの通り。
grep $(date +%d"/"%b"/"%Y --date "1 day ago") 3.2で抽出したログの中から、https://tech-memo.net/以降の文字列だけを抽出。
具体的には7カラム目を抽出。
awk '{print $7}' 4.3で抽出した文字列に対し、重複しているものを1つに抽出。
特技sort&uniqコンボ。
sort -n | uniq 5.4で抽出した文字列に対し、</archives/>という文字列だけを削除。(.htaccessに記述しやすくするため)
sedで置換。/(スラッシュ)を#(シャープ)で代用。
sed -e 's#\/archives\/##g'6.5で抽出した文字列に対し、<cat_>という文字列を含む結果行を削除。
タイトルの通り。
grep -v "cat_"7.6で抽出した文字列に対し特定のファイルへのアクセス先の行は削除し、再度重複を削除
理由はわからないが、 archives/8250467.html***という文字列が出力されることがあり単純に邪魔だったので削除。
awk '{ sub(".html.*", ""); print $0;}'| uniq8.7で抽出した文字列で不要な文字列を削除しhoge.txtというファイルに出力
archives、favicon等直接記事と関係ないアクセスを削除。
grep -v -E 'archives|favicon' | sed 's#\*\*\*##g' > hoge.txt9.backupdata.txtというエクスポートファイルを整形したテキストに対して、出力したhoge.txtの中の文字列を1行づつgrepで検索し、最終的な結果をログに出力。
なんか色々ぶち込んでいるけれどタイトルの通り。
for i in `grep -v "-" hoge.txt` ; do grep -B1 ${i} ./backupdata.txt | sed -e 's#archives\/##g' ;
done > ./logs/404chk_`date +%Y%m%d%H%M`.log以上。
backupdata.txtの中身
記事のタイトルと、FQDN配下のパスが記載されている。具体的には以下の通り。
TITLE: VBAメモ1
PATH: archives/4017768.html
TITLE: VBA2
PATH: archives/4017777.html
TITLE: VBAでCase文で特定の値を含むセルの色を変えるコード
.......5月23日に実行したスクリプトの結果
こんな感じ。
TITLE: パブリックDNSリスト
PATH: archives/5307882.html
TITLE: Javascript PC Emulator(jslinux)
PATH: archives/8250467.htmlこの汚ワンライナーの問題点
1.純粋に汚い。この汚さが美しいと言える心の美しさを手に入れたい。
2.設計思想の項番6の<cat_>~の下りは実はカテゴリーを検索したときに出力されるものなのだが、カテゴリーに対してアクセスして404エラー吐いている接続には対応していない。(面倒くさいから)
3.2同様、スクリプトの解説の項番7のarchives/8250467.html***というアクセスにはあえて対応せず。(面倒くさいから)
4.hoge.txtというゴミファイルが毎回生成され毎回上書きされる。スクリプト内で消せよ。
結論
なんだかんだ言って、このシェルのお陰で手作業の工数が8割くらい削減できた。シェルスクリプトって便利よねー。
でも汚く書きすぎると後の人がメンテできなくなって負の遺産になってしまうので気を付けないといけないね。

後日談
結局面倒臭くなったのでスクリプトに作り直し、毎晩0時にcronで実行することにした。
めでたしめでたし。

コメント